Claude Code 进阶:深入理解MCP和Skills
过去两年,我一直在观察和使用 AI 编程工具,看着它们从简单的代码补全,一步步演变成今天的智能协作者。
回想一下,大概经历了这几个阶段:
代码补全时代(2023 初):GitHub Copilot 那样,根据你写的代码预测下一行。本质是"高级自动完成",挺方便,但理解深度有限。
对话式编程(2023-2024):GPT-4、Claude 3.5 出来后,你可以用自然语言描述需求,AI 能生成跨文件的代码片段、做重构解释。从被动补全变成了主动对话。
智能体时代(2024-2025):这是最近的变化。AI 不再是被动响应,而是能自主规划、执行、反思。上下文工程解决了大型代码库的理解问题,RAG 和代码知识图谱让它能"看见"整个项目;工具调用(MCP)让它能读写数据库、执行命令;任务规划能力让它能把"做一个用户管理系统"拆解成具体步骤并执行。
产品形态也从 IDE 插件扩展到独立 AI IDE(Cursor、Trae)、CLI 工具(Claude Code)、云端平台(Replit)。
现在的问题已经不是"AI 能不能做",而是"怎么让它做得更好、更符合我的习惯"。掌握这些工具,本质上是在解放自己的时间。把重复的编码工作交给 AI,我们才能把精力花在更有价值的事情上:思考架构、学习新技术、健身、陪伴家人……这才是技术进步的真正意义。
好了,废话不多说,咱们先来Claude Code 的 MCP 和 Skills 两个特性,下篇文章将着重写MCP与Skills实战系列,让 AI 从通用助手变成了可定制的"团队成员"。
MCP:模型上下文协议
MCP 是什么
模型上下文协议 (Model Context Protocol, MCP) 是 Anthropic 在 2024 年 11 月推出的开源通信标准。它的目标是标准化 AI 模型与外部数据源、工具的连接方式。
如果把不同的大模型看作不同品牌的电脑主机,MCP 就像是统一的 USB-C 端口。无论你要连接 PostgreSQL 数据库、GitHub API、本地配置文件,还是公司内部系统,只要 MCP Server 符合标准,就能即插即用。
为什么 MCP 重要
传统 AI 应用集成的痛点是接口碎片化。每个数据源都需要定制化的连接器和 Prompt 描述,开发维护成本高,难以复用。MCP 通过协议统一与责任分离解决这个问题:
-
统一协议层:MCP 定义了基于 JSON-RPC 2.0 的标准消息格式和通信机制(Stdio 和 HTTP with SSE),所有交互都遵循此规范。
-
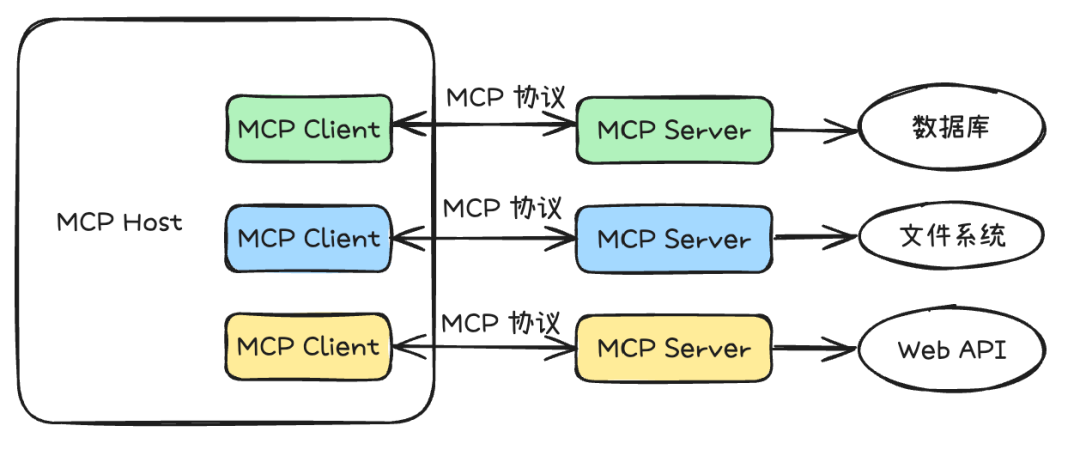
清晰的 C/S 架构:
- Host:用户直接交互的应用,如 Claude Desktop、Claude Code,内置 MCP Client
- MCP Server:提供具体能力的轻量级独立进程,如访问数据库、执行搜索
- 数据源:通过 MCP Server 安全访问的本地文件、数据库或远程 API
这种设计将 AI 的"思考"(LLM)与"执行"(访问外部世界)解耦。LLM 只需知道自己能通过 MCP 调用工具,无需关心工具背后的实现。这解决了 AI 无法直接访问实时数据、执行外部操作或触及私有数据的问题。
MCP 调用流程
一个典型的 MCP 调用流程:
- 信息输入:用户向 Host 提问,Host 将问题 + 所有已配置的 MCP Server 工具描述发送给 LLM
- 决策与规划:LLM 判断需要调用哪个工具,返回工具名和参数
- 协议化执行:Host 内的 MCP Client 启动,将请求封装为 MCP 标准格式发送给对应的 MCP Server
- 获取结果:MCP Server 执行操作(如查询数据库),将结果封装为 MCP 格式返回
- 整合与输出:Host 将原始问题 + 工具执行结果再次发送给 LLM,LLM 整合信息生成最终答案
MCP 协议仅规范了 Client 与 Server 间的通信。LLM 接收到的"工具说明书"可以是 System Prompt 中的文本,也可以是类似 Function Calling 的结构化格式。这取决于 Host 的实现。
Skills:封装领域知识
如果说 MCP 给了 Claude "手"和"眼",Skills 则是为它注入"领域经验"和"肌肉记忆"。
Skills 是什么
Skills 是 Claude Code 的核心特性,允许你将工作流程、最佳实践、领域知识封装成可复用的模块(本质上是一个包含 SKILL.md 等文件的目录)。
它的三级加载机制平衡了能力与上下文开销:
- Level 1: 元数据(始终加载) - 技能名称和简短描述,供 Claude 索引
- Level 2: 说明文档(触发时加载) - 用户问题匹配技能描述时,Claude 才读取
SKILL.md加载详细指令 - Level 3: 资源与代码(按需加载) - 脚本、配置文件仅在需要执行时才通过 bash 调用,代码本身不占 Token
编写自定义 Skills
你可以将个人或团队经验封装成 Skills。例如创建一个 ddd-code-review Skill,封装 DDD 实践中的代码规范,在 SKILL.md 中定义实体、聚合根、领域服务的识别规则与分层架构检查点。
一个简单的 Skill 目录结构示例:
my-ddd-skill/
├── skill.json # 元数据
└── SKILL.md # 核心知识文档
skill.json 示例:
{
"name": "my-ddd-arch-skill",
"description": "遵循领域驱动设计(DDD)规范进行代码生成与重构的指导技能。强调战术建模的纯粹性、聚合根的不变性以及领域层的隔离性。",
"version": "1.0.0",
"skill": {
"file": "SKILL.md"
}
}
SKILL.md 核心:用清晰的指令定义代码风格、架构规则、检查清单。当 Claude 启用此技能后,它的所有代码生成与重构行为都会自动对齐你的架构规范。
MCP 与 Skills 的区别
解决的问题域不同
MCP:解决"信息孤岛"与"能力接入"问题
- 痛点:AI 无法实时访问数据库、调用内部 API、读写本地特定文件
- 方案:提供统一的协议层。开发者只需遵循 MCP 标准封装一个 Server(如用 FastMCP 写几十行),AI 就能通过标准接口安全调用该能力
Skills:解决"知识碎片化"与"执行不稳定"问题
- 痛点:每次都需要在 Prompt 中重复长篇大论的领域规则(如 DDD 规范、代码审查清单),消耗大量 Token 且效果不稳定
- 方案:提供渐进式加载的知识封装机制。通过三级加载(元数据→指令→资源),让 AI 仅在需要时才获取详细指南,节省上下文窗口
关键特性对比
| 特性 | MCP | Skills | 架构意义 |
|---|---|---|---|
| Token 消耗 | 较高。启动时需加载所有可用工具的完整描述到上下文,可能达数万个 Token | 极低(按需)。仅元数据常驻(约 100 Token),详细指令按需加载 | Skills 在上下文窗口管理上更具优势 |
| 开发门槛与复用性 | 门槛较高。需要编写和部署独立的 Server 进程,涉及网络、安全、协议兼容性。但一旦开发完成,可在任何支持 MCP 的平台复用 | 门槛极低。核心是撰写清晰的 Markdown 文档,开发者甚至业务专家都可参与创建。复用性同样跨越平台 | Skills 大幅降低了 AI 能力封装的门槛 |
| 职责边界 | 告诉 AI"有什么工具可用"以及"工具如何调用"(What & How to call) | 告诉 AI"在什么场景下、按照什么流程、使用哪些工具"(When & Which & Flow) | Skills 是"战术手册",MCP 是"武器库"。二者互补,Skills 可指挥 MCP |
MCP 与 Skills 的协作关系
MCP 为 AI 配备了标准化的"手"和"眼"(及全套工具),Skills 为 AI 植入了"肌肉记忆"和"领域经验"。
二者在 Agent 工作流中的协同方式:
用户意图
↓
Agent (大脑: LLM)
├─── Skills (领域知识顾问)
│ ↓ (按需加载: "这件事的标准做法是...")
└─── MCP (外部执行臂)
↓ (协议调用: "请帮我查询数据库")
MCP Server (外部工具)
↓ (执行并返回结果)
实践建议
-
先用 Skills 固化工作流:将团队内部的代码规范、架构评审清单、部署 SOP 封装成 Skills。这是提升日常 AI 协作效率最快、ROI 最高的投资
-
再用 MCP 突破能力边界:当 AI 需要接入公司数据库、内部监控系统或第三方 API 时,基于 MCP 开发定制 Server
-
Skill + MCP 协同:例如创建一个
database-refactorSkill,其内部指引 AI 调用配置好的postgres-mcpServer 去分析表结构,再结合 Skill 中定义的性能优化范式生成重构方案
未来的 AI 工程竞争力,不在于你使用了哪个孤立的组件,而在于能否以架构思维,将代表"外部能力"的 MCP 与代表"内部智慧"的 Skills 融合,构建出深度理解业务的智能体系统。